
Docker swarm is an orchestration tool, similar to Kubernetes, but simpler to set up and manage. A swarm consists of multiple Docker hosts which run in swarm mode and act as managers (to manage membership and delegation) and workers (which run swarm services). A given Docker host can be a manager, a worker, or perform both roles.
The docker swarm feature is embedded in the Docker Engine (using swarmkit). This means you don’t need to install extra packages to use it. You just docker. If you decided to put it in place, one of the open problems to address is the persistent storage.
In the old days, many processes could share a local disk on the host. It was a common pattern to have a process that writes to files, and another that consumes them. The two processes were living happily on the same host, having no problems working together. But it’s another story in the containerized world. When containers are managed by an orchestrator, you can’t really tell where your container would be scheduled to run. It won’t have a permanent host, neither you want to lock it to a specific host, as you lose many of the orchestrator benefits (resiliency, fail-over, etc.).
The Problem: Data Persistency on the Swarm cluster
Suppose you have two services that need to share a disk, or a service that requires data persistency such as a Redis. What are your options?
One easy option is to use docker volumes. It’s a good option if you run on a single node because when you create a new docker volume, it resides on the host it was created on.
But what happens when it runs on a cluster? good question. Let’s walk through an example. I’m going to one from the use the Docker Documentation (Get Started with Docker Compose)
Here are the files I’m using for this example:
| |
| |
| |
| |
Suppose you have a small cluster of 3 nodes. (Their roles in the cluster don’t matter for example). You run your docker-compose file with your app and a Redis instance, and define a volume for it. The first time you run your docker-compose, docker creates the volume and mounts it to your service on startup.
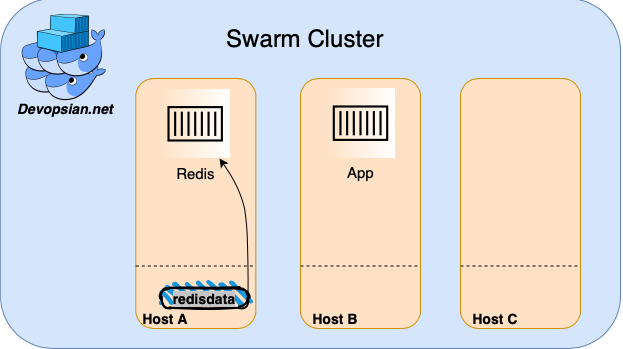
Now you want to deploy a new version of your service. The cluster decides to schedule the Redis instance on a different node than before. What will happen to your volume?
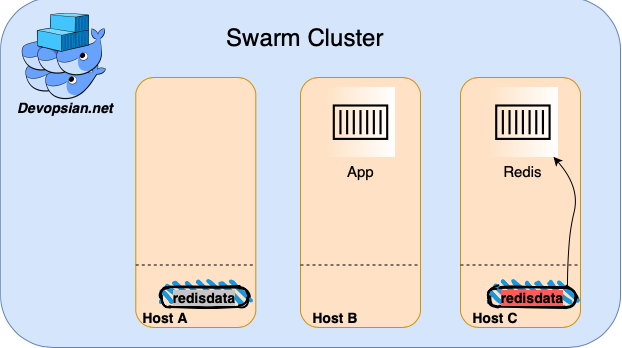
Since the volume doesn’t exist on the node the service runs at, docker would create a new volume with the same name on the new node. The previous volume still exists with the data but, it resides on the old node. The Redis service has no access to it. Redis now actually has a new, empty volume for use. You end up in an inconsistent state. This solution doesn’t work for us.
AWS Elastic File System (EFS)
Amazon Elastic File System (Amazon EFS) provides a simple, scalable, fully managed elastic NFS file system for use .. It is built to scale on-demand to petabytes without disrupting applications, growing and shrinking automatically as you add and remove files, eliminating the need to provision and manage capacity to accommodate growth.
EFS provides a NFS volume you can mount at runtime. The swarm cluster schedules to run the service on one of its nodes and mounts the NFS volume to the container.
With these configurations, if the cluster decides to move our Redis service to a different node (due to a failure, deployment, etc.), the mount (and hence the data) will move to the new node too. I won’t go through how to create an EFS volume, you can find the steps here on aws tutorial.
To achieve that, we need to install the nfs-common package on the swarm nodes. On Ubuntu, you can install it with: sudo apt-get install nfs-common
Next, we will update the volumes definition of our docker-compose, with the new driver type and the address. It looks as follows:
| |
When we run our app now, the Redis data volume is persistent. It will move with it to whatever node Redis runs on.
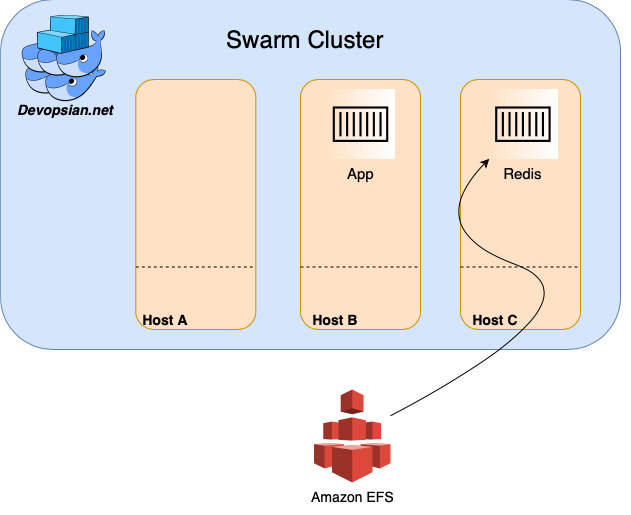
This solves our original problem. We now have a way to persist data across our cluster.
Costs
This blog post uses AWS as the cloud infrastructure. When comparing EFS, the closest service AWS I could find is EBS volumes. I assume you’re familiar with it.
You should use these pricing calculators from AWS to tailor the price for your use case.
These are not apples to apples, but let’s do a quick price comparison between the two. We will compare a 100GB volume in the EU region.
EBS
| Type | Charged for | Price |
|---|---|---|
| Storage | 0.088$/GB * 730 * 100 | $64.24 |
| IOPS | 3K - included | $0 |
| Throughput | 125MB/s - included | $0 |
You can increase the throughput or IOPS, with additional costs.
EFS
With EFS, the charges are different (shocked ah?). You pay for “Standard Storage Class” which is designed for active file system workloads.
You pay a different price for “Infrequent Access Storage Class” (IA) which is cost-optimized for files accessed less frequently. For this comparison, let’s estimate 50% of the data is frequently accessed.
| Type | Charged for | Price |
|---|---|---|
| Standard Storage | 0.33$/GB monthly * 50 | $16.5 |
| IA Storage | 0.025$/GB monthly * 50 | $1.25 |
| Throughput | 2.5MB/s included, 6.60$ per additional MB/s | $0 |
The throughput part is kinda tricky. You get 50KB/s per Stand Storage GB (50GB * 50KB = 2.5MB/s) for write operations and 150KB/s (50GB * 150KB = 7.5MB/s) for read operations.
As you see, there is a big performance impact when comparing EBS with EFS. If you need high throughput, EFS might get very expensive.
Conclusion
The problem I wrote about in this blog is a known problem when running microservices on a managed cluster using an orchestration tool. As with other problems, it has more than one solution where each has its trade-offs.
I showed that EFS is a convenient, easy solution you can use to solve the shared storage problem. Yet, it is not the right solution for everything. The performance is limited, and it can get very expensive if your app requires high throughput. In those cases, you would want to use something else.
If you can compromise on the throughput, EFS becomes an attractive option to manage your cluster shared storage.
When you define your NFS volumes inside your docker-compose file, it is part of the service definition. It takes care of the infrastructure it uses. I find this pattern a good one when dealing with microservices. If you need to move this service to another cluster, anytime in the future, the NFS mount is one thing less you need to remember to do.